The Intelligence Layer for All Technology
Snow Software is the only unified cloud-native platform delivering actionable insights on your IT environment. Bringing together SaaS management, software asset management and cloud cost management, you can optimize IT spend, rein in cost, mitigate risk and drive value from all your technology.
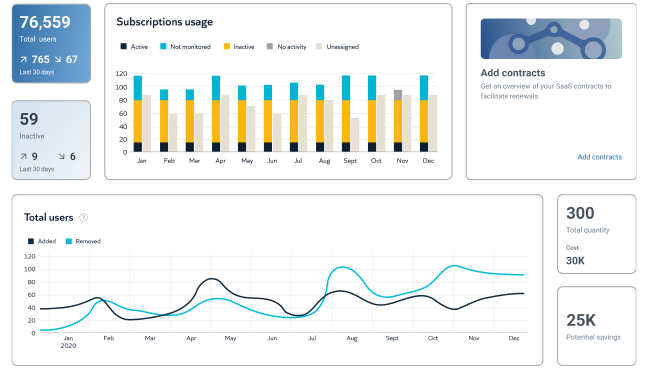
Flexera and Snow: Unprecedented Visibility and Insights
Snow Software is now a part of Flexera. The combined entity is on a mission to deliver comprehensive technology data and intelligence for all. We strive to provide unprecedented visibility and insights across your entire IT environment, helping you drive positive business outcomes whether that’s to optimize spend, mitigate risk, adapt to uncertainty or invest in innovation initiatives like artificial intelligence.
Learn More
See How we help organizations just like yours
-
SaaS Management
Reduce financial and security risk with a complete view
of known, free and
shadow SaaS usage.
-
Cloud Cost Management
Monitor and manage your spending across public cloud accounts, including Amazon Web Services, Microsoft® Azure®, Google Cloud Platform and Kubernetes.
-
Cloud Cost for Managed Service Providers
Deliver profitable and differentiated cloud cost management services.
-
Total Cost Optimization
Remove redundant software licenses, discover unused applications, and reduce cloud costs to optimize spending across your IT landscape.
-
Audit Defense
Complete and accurate visibility into all the technology used in your organization, including cost data, software license entitlements and agreements.
-
Cloud Management
Cloud management tools and expertise can help you increase visibility and boost business agility, efficiency and oversight.
Snow Success Story Spotlight: Sasol
Sasol manages 23,000 devices in 30 countries from a single location with Snow Software. With the clarity and visibility provided by Snow’s solutions, Sasol was able to save more than $34 million while lowering carbon emissions as part of their drive to streamline and build a more sustainable business.
Read the story